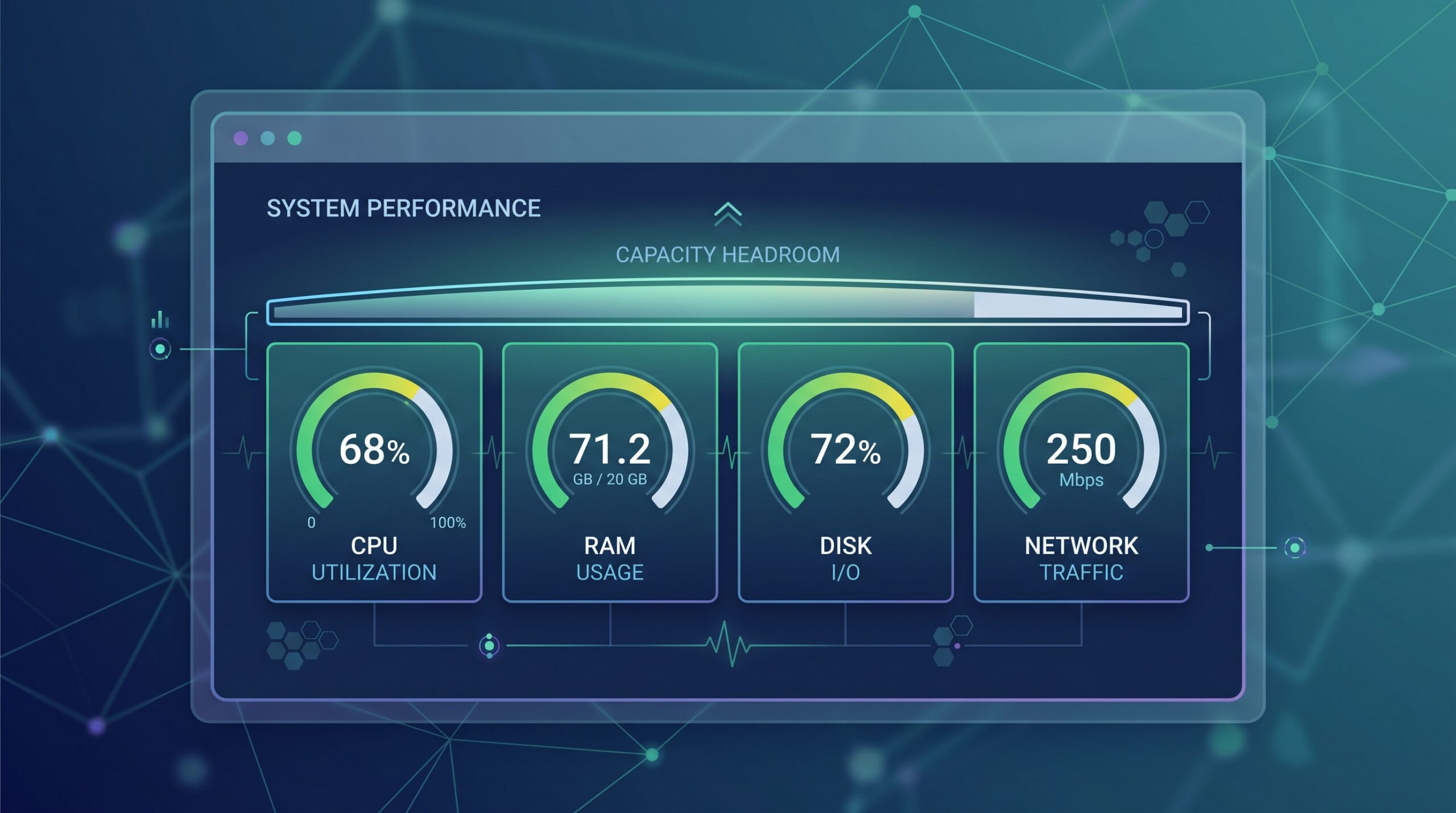
Почему 70% – это новая золотая середина для IT-инфраструктуры?
Правило «не более 70%» строится на концепции запаса прочности (headroom). Система, работающая на пределе, неизбежно теряет стабильность и отклик. Оставляя свободными 20–30% ресурсов, вы создаете буфер, который помогает:
- Справляться с пиковыми нагрузками. Внезапный наплыв пользователей или запуск тяжелой фоновой задачи не положат сервер.
- Сохранять скорость. Ресурсов хватает для выполнения процессов на лету, без задержек и «тормозов».
- Беречь оборудование. Компоненты в щадящем режиме меньше греются и медленнее изнашиваются.
- Упрощать обслуживание. У вас остается пространство для маневра: можно внедрять новые функции и проводить техработы без остановки сервисов.
Влияние перегрузки на ключевые IT-компоненты
Процессор (CPU): Больше, чем просто скорость
Процессор — мозг системы. Если он постоянно загружен выше 70–80%, ждите проблем:
- Троттлинг: Чип принудительно сбрасывает частоту, чтобы спастись от перегрева. Результат — резкое падение производительности.
- Рост задержек: Задачи выстраиваются в очередь, система начинает «думать» дольше.
- Нестабильность: Перегрев провоцирует ошибки, синие экраны (BSOD) и внезапные перезагрузки.
- Износ: Постоянно высокие температуры буквально разрушают кремниевые кристаллы.
Чем мониторить: Диспетчер задач (Windows), top/htop (Linux), Prometheus + Grafana, Zabbix.
Оперативная память (RAM): Когда свобода – это производительность
Оперативная память нужна для мгновенного доступа к данным. Как только загрузка переваливает за 70%, система включает свопинг — начинает сбрасывать «лишние» данные на медленный диск (в файл подкачки).
- Катастрофическое замедление: Диск в тысячи раз медленнее RAM, поэтому производительность рушится на глазах.
- Износ SSD: Бесконечная перезапись файла подкачки «сжигает» ресурс твердотельников.
- Зависания: Приложения перестают отвечать на запросы или открываются целую вечность.
Чем мониторить: Системные мониторы ОС, команда free -h в Linux.
Дисковые накопители (HDD/SSD): Запас – друг долговечности
Диск — это не просто хранилище файлов, а фундамент для работы ОС. Если свободного места остается меньше 30%:
- Для HDD: Растет фрагментация данных. Магнитная головка вынуждена метаться по всему диску, скорость чтения и записи резко падает.
- Для SSD:
- Снижается скорость: Контроллеру сложнее искать пустые блоки для алгоритмов сборки мусора (Garbage Collection).
- Ускоряется смерть накопителя: Ячейки памяти перезаписываются неравномерно, что быстро истощает их ресурс.
- Сбои команды TRIM: Недостаток места ломает механизмы самоочистки диска.
- Проблемы с ПО: Банально не хватает места для распаковки временных файлов при обновлениях.
Чем мониторить: Свойства диска в ОС, df -h в Linux, утилиты S.M.A.R.T.
Сетевое оборудование: Узкие места в цифровых коммуникациях
Когда сетевой канал забит более чем на 70–80%, инфраструктура начинает захлебываться:
- Потеря пакетов: Буферы роутеров переполняются, и оборудование просто отбрасывает часть данных.
- Рост пинга (latency): Пакеты ждут своей очереди. Для IP-телефонии, видеосвязи и онлайн-игр это критично.
- Слом QoS (качества сервиса): Механизмы приоритизации важного трафика перестают работать адекватно.
- Ошибки в софте: Приложения, чувствительные к сетевым задержкам, сыплют ошибками соединения.
Чем мониторить: Инструменты анализа трафика (NetFlow, sFlow), утилиты iperf, PingPlotter.
Что дает соблюдение правила «не более 70%»
Практические выгоды от наличия запаса ресурсов:
- Железобетонная стабильность: Минимум сбоев, зависаний и внезапных перезагрузок.
- Высокая скорость: Система мгновенно откликается даже под серьезной нагрузкой.
- Долгая жизнь оборудования: Компоненты не перегреваются, их реже приходится менять. Оптимальная загрузка серверов и другого IT-оборудования снижает тепловыделение, что создает благоприятные условия для применения энергосберегающих технологий охлаждения, таких как фри-кулинг.
- Готовность к стрессам: Пиковые наплывы трафика проходят незаметно для пользователей.
- Удобство диагностики: Свободные ресурсы позволяют без боли ставить обновления, снимать логи и искать баги.
- Экономия денег: Меньше простоев — меньше убытков для бизнеса. Правильный выбор уровня загрузки напрямую влияет на экономическую эффективность и окупаемость энергоэффективного оборудования, поскольку позволяет минимизировать эксплуатационные расходы.
- Довольные пользователи: Клиенты и сотрудники получают быстрые и надежные сервисы.
Как удержать системы в рамках «золотой середины»?
Чтобы не выходить за безопасные пределы загрузки, используйте следующие подходы:
- Настройте мониторинг: Для достижения оптимальной загрузки IT-компонентов и эффективного управления ресурсами критически важен IoT-мониторинг энергопотребления для бизнеса, позволяющий отслеживать и анализировать данные в реальном времени. Внедрите Zabbix, Prometheus + Grafana или ELK Stack. Задайте алерты на превышение порога в 70–80%, чтобы узнавать о проблемах до того, как они станут критичными.
- Планируйте емкость (Capacity Planning): Понимание и расчет мощности IT-компонентов является фундаментальным шагом для определения их оптимальной загрузки и избежания как перегрузки, так и недогрузки. Прогнозируйте рост нагрузки по историческим данным. Закупайте ресурсы на шаг впереди реальных потребностей.
- Оптимизируйте софт: Ищите «тяжелые» запросы к БД, утечки памяти в коде и лишние фоновые процессы. Избавляйтесь от мусорного ПО.
- Масштабируйтесь: Если загрузка стабильно высока — добавляйте серверы, память или ширину канала. В облаке обязательно используйте автоскейлинг.
- Автоматизируйте рутину: Настройте скрипты для автоматической очистки логов, кэша и старых временных файлов.
- Архивируйте старое: Переносите редко используемые («холодные») данные на дешевые хранилища, разгружая быстрые основные диски.